Infrastructure partagée, locataires isolés : la mutualisation multi-tenant avec Amazon Bedrock AgentCore
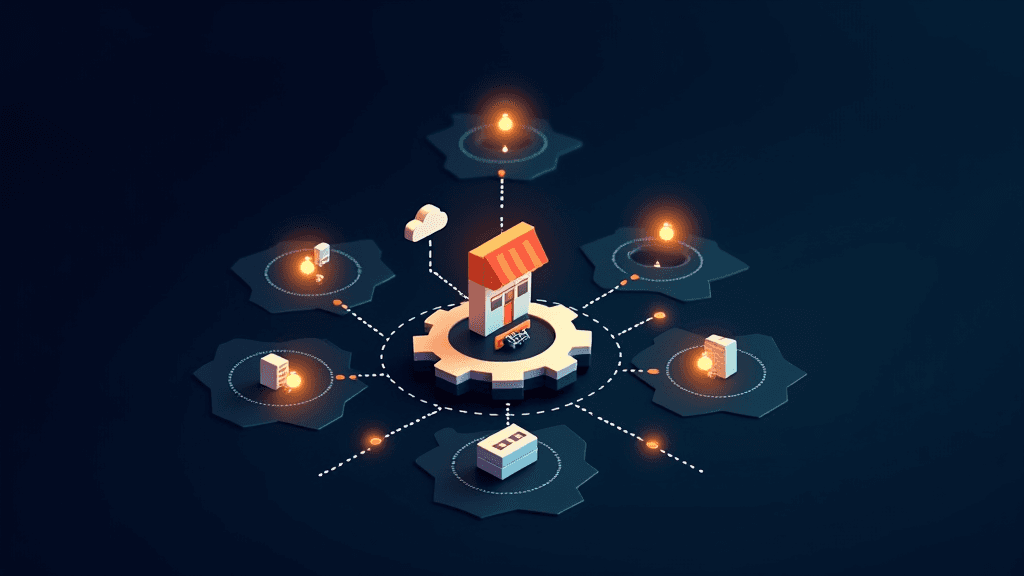
Amazon Web Services vient de publier un guide architectural détaillé pour la construction d'applications d'intelligence artificielle multi-locataires à l'aide d'Amazon Bedrock AgentCore. Le document, second volet d'une série consacrée à ce sujet, s'appuie sur un cas concret dans le domaine médical : une plateforme d'agents IA servant simultanément plusieurs cliniques et hôpitaux. L'architecture proposée repose sur un modèle dit "pool", où tous les clients partagent la même infrastructure sous-jacente, mais sont isolés les uns des autres par des mécanismes logiques : identifiants scopés, politiques d'accès et partitionnement des données. La hiérarchie est structurée en trois niveaux, Niveau de service, Locataire, Utilisateur, et l'isolation est appliquée à chaque couche, depuis les documents stockés en base de connaissances jusqu'au suivi des coûts. Ce schéma répond à un défi concret pour les éditeurs de logiciels en mode SaaS : comment servir des clients aux besoins très différents sans multiplier les infrastructures dédiées ni exposer des données d'un client à un autre ? La solution présentée définit deux niveaux de service distincts. L'offre basique, destinée aux petites cliniques, utilise le modèle Mistral Ministral 3 8B Instruct pour des tâches de recherche documentaire simples, avec un coût réduit. L'offre premium, réservée aux hôpitaux et centres spécialisés, s'appuie sur OpenAI GPT OSS 120B, un modèle de 120 milliards de paramètres aux capacités de raisonnement avancées, et donne accès à des outils supplémentaires comme la recherche web. Cette différenciation par niveaux permet à un même fournisseur de servir des clients aux exigences très différentes tout en maintenant une efficacité opérationnelle. Le contexte est celui d'une adoption croissante des agents IA dans les entreprises, qui soulève des questions de gouvernance, d'attribution des coûts et de qualité de service que les architectures classiques ne résolvent pas facilement. Amazon positionne Bedrock AgentCore comme une brique native pour absorber cette complexité sans code personnalisé excessif. La publication du dépôt GitHub associé aux exemples illustre une volonté de standardisation des pratiques : l'objectif est que les équipes techniques puissent répliquer ces patterns dans des secteurs variés, plateformes SaaS, solutions d'entreprise multi-entités, services managés. Les enjeux sont significatifs, car une mauvaise isolation entre locataires dans un contexte médical exposerait des données sensibles de patients, avec des conséquences réglementaires sévères. Ce cadre architectural cherche précisément à rendre ce risque gérable par conception plutôt que par surveillance manuelle.
UELes éditeurs européens de SaaS dans le secteur médical peuvent s'appuyer sur ces patterns d'isolation multi-tenant pour faciliter la conformité au RGPD, même si la solution repose intégralement sur l'infrastructure américaine d'AWS.