Flux sensoriel modulaire pour intégrer le feedback physique dans les modèles vision-langage-action
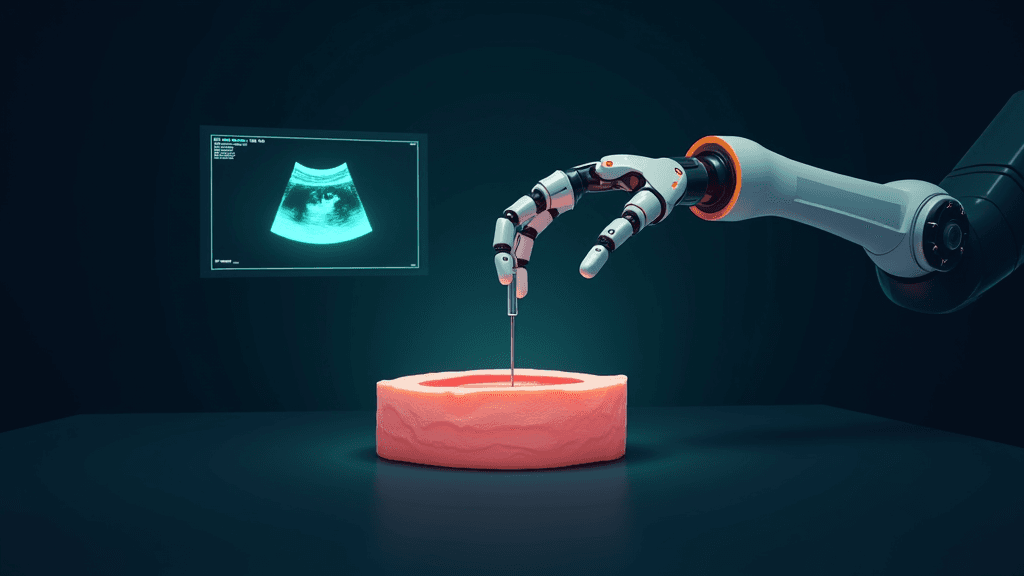
Des chercheurs ont publié fin avril 2026 sur arXiv un article présentant MoSS (Modular Sensory Stream), un cadre modulaire conçu pour enrichir les modèles Vision-Langage-Action (VLA) avec des retours physiques multiples. Les VLA sont des systèmes d'intelligence artificielle utilisés en robotique pour interpréter des scènes visuelles et du langage naturel afin de générer des actions. MoSS introduit des flux de modalités découplés qui intègrent des signaux physiques hétérogènes, notamment tactiles et de couple mécanique (torque), directement dans le flux d'action du modèle via un mécanisme d'attention croisée. Un schéma d'entraînement en deux étapes, où les paramètres du VLA préentraîné sont d'abord gelés, assure une incorporation stable des nouvelles modalités. Des expériences en conditions réelles démontrent des gains de performance synergiques lorsque ces signaux sont combinés.
L'enjeu est considérable pour la robotique de manipulation. Aujourd'hui, la grande majorité des VLA reposent quasi exclusivement sur la vision, ce qui les rend aveugles aux informations que procure le toucher ou la résistance mécanique lors d'un contact. Un robot vissant un écrou, saisissant un objet fragile ou détectant un glissement ne peut s'appuyer sur la caméra seule pour ajuster sa prise en temps réel. MoSS montre que l'ajout de signaux tactiles et de couple, traités en parallèle plutôt qu'en série, améliore la précision des actions de manière complémentaire, chaque modalité compensant les angles morts des autres.
Les VLA sont devenus l'un des fronts les plus actifs de la recherche en robotique depuis l'émergence de modèles comme RT-2 (Google DeepMind) ou OpenVLA. La tendance dominante consistait jusqu'ici à enrichir la composante visuelle ou langagière de ces systèmes, en négligeant les sens physiques que les humains mobilisent naturellement pour manipuler des objets. MoSS s'inscrit dans un courant émergent qui cherche à doter les robots d'une perception proprioceptive et haptique plus fine. La nature modulaire du framework facilite l'ajout de nouvelles modalités sensorielles à l'avenir, ce qui ouvre la voie à des robots capables d'intégrer température, vibration ou pression sans nécessiter une refonte complète de l'architecture.
Dans nos dossiers
Vu une erreur factuelle dans cet article ? Signalez-la. Toutes les corrections valides sont publiées sur /corrections.