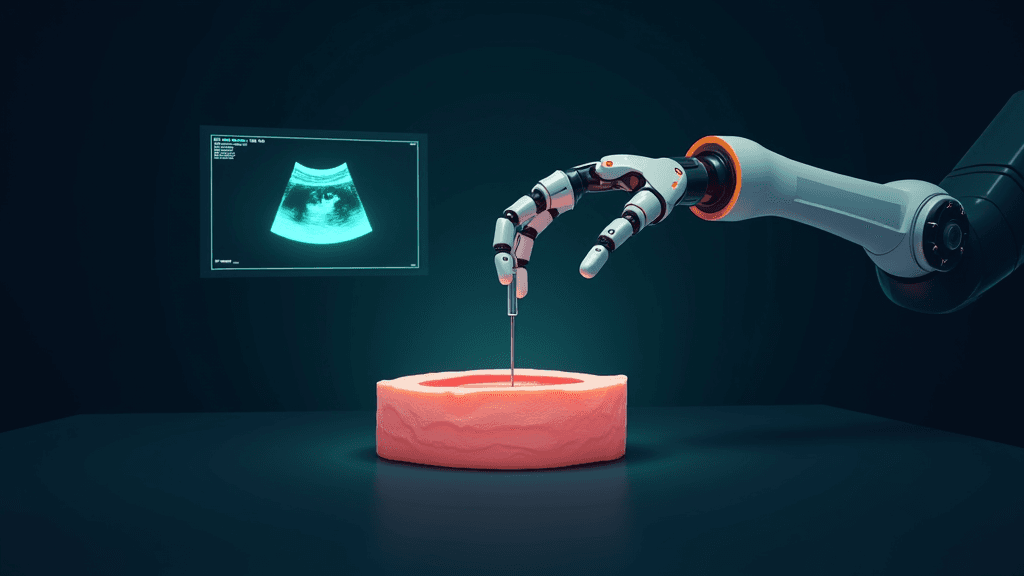
PokeVLA : un modèle vision-langage-action compact enrichi d'une connaissance globale du monde
Des chercheurs ont publié PokeVLA, un nouveau modèle de fondation léger conçu pour la manipulation robotique, présenté dans un article déposé sur arXiv fin avril 2026. Le système repose sur une architecture Vision-Language-Action (VLA) qui intègre la compréhension visuelle et linguistique directement dans l'apprentissage des actions physiques d'un robot. Pour y parvenir, l'équipe a développé une approche en deux étapes : d'abord, un modèle vision-langage compact baptisé PokeVLM est pré-entraîné sur un jeu de données soigneusement constitué de 2,4 millions d'échantillons couvrant l'ancrage spatial, les affordances et le raisonnement incarné ; ensuite, des représentations spécifiques à la manipulation sont injectées dans l'espace d'action via un apprentissage sémantique multi-vues, un alignement géométrique et un module d'action inédit. Les expériences montrent des performances de pointe sur le benchmark LIBERO-Plus ainsi qu'en déploiement réel, surpassant les modèles comparables en taux de réussite et en robustesse face à diverses perturbations. Le code, les poids du modèle et les scripts de préparation des données seront rendus publics.
Ce travail s'attaque à deux limites majeures des modèles VLA existants : leur inefficacité computationnelle et leur faible capacité à raisonner à haut niveau sur l'espace et les objets. En proposant un modèle à la fois compact et performant, PokeVLA ouvre la voie à des robots capables de comprendre leur environnement de manière plus fine sans nécessiter des ressources matérielles considérables. Pour l'industrie de la robotique, cela signifie que des systèmes plus accessibles pourraient atteindre des niveaux de fiabilité jusqu'ici réservés aux modèles volumineux, accélérant potentiellement l'adoption dans des contextes réels comme la logistique, la fabrication ou les soins à domicile.
Les modèles VLA connaissent une montée en puissance rapide depuis que des travaux comme RT-2 de Google ou OpenVLA ont démontré l'intérêt de combiner grands modèles de langage et contrôle moteur. La tendance générale pousse vers des modèles toujours plus grands, mais PokeVLA prend le contre-pied en cherchant la compacité sans sacrifier les capacités. La mise en open source annoncée est stratégique : elle permettra à la communauté académique de reproduire les résultats et d'itérer rapidement, ce qui pourrait accélérer l'émergence de robots généralistes abordables dans les prochaines années.
Dans nos dossiers
Vu une erreur factuelle dans cet article ? Signalez-la. Toutes les corrections valides sont publiées sur /corrections.