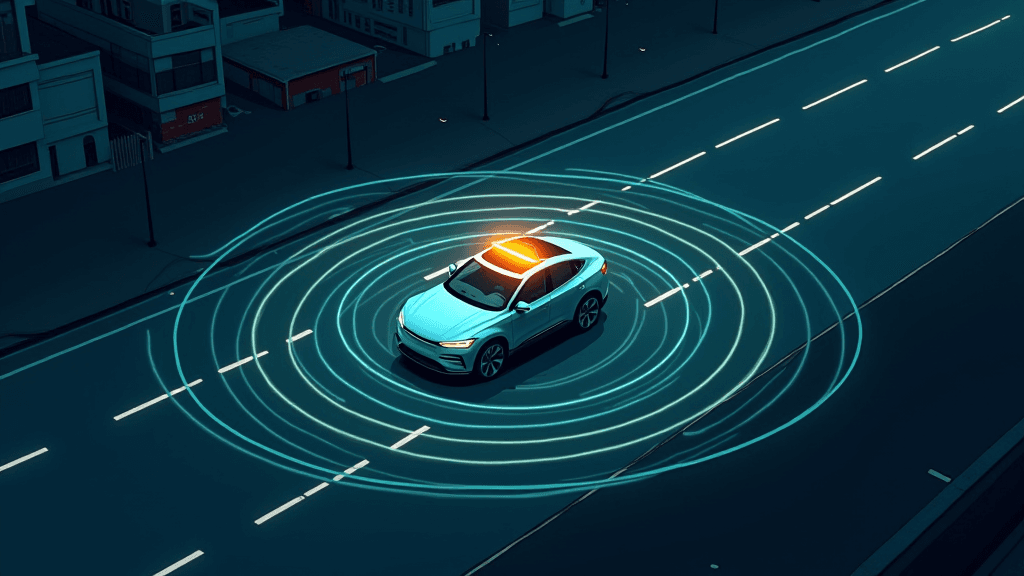
Décision interactive pour la conduite autonome par grands modèles de langage
Des chercheurs ont publié sur arXiv un nouveau cadre de prise de décision pour véhicules autonomes, conçu spécifiquement pour les situations de trafic mixte à forte densité où coexistent voitures humaines et autonomes. Le système exploite les grands modèles de langage non pour générer du texte, mais pour analyser dynamiquement la scène routière et inférer les intentions des autres usagers. Il repose sur l'Object-Process Methodology (OPM), qui traduit les données perceptuelles brutes en objets, processus et relations compréhensibles par le modèle. Celui-ci identifie ensuite les intentions explicites et implicites des véhicules voisins, génère des trajectoires candidates par échantillonnage Monte Carlo, et sélectionne la trajectoire optimale sous contraintes conjointes de sécurité et d'efficacité. La décision finale est retranscrite en langage naturel et diffusée aux autres usagers via une interface homme-machine externe (eHMI). Testé dans un simulateur de conduite en convoi, le système surpasse les approches traditionnelles sur les critères de sécurité, confort et fluidité, et un test de style Turing révèle une forte ressemblance avec les comportements humains au volant.
Ce travail s'attaque à l'un des principaux freins à l'adoption des véhicules autonomes : leur tendance aux comportements excessivement prudents dans les situations conflictuelles, qui génèrent blocages et méfiance du public. En dotant le véhicule d'une capacité de lecture des intentions des autres conducteurs et d'une communication proactive en langage naturel, le cadre proposé change la nature de l'interaction : il ne s'agit plus seulement d'éviter les accidents, mais d'expliquer en temps réel les décisions du robot pour instaurer une confiance partagée avec les piétons, cyclistes et automobilistes environnants.
La conduite autonome en environnement mixte reste l'un des défis les plus complexes du secteur, au croisement de la robotique, des sciences cognitives et de l'IA générative. Des acteurs comme Waymo ou Mobileye investissent massivement dans ces problèmes d'interaction homme-machine. L'intégration des LLMs dans la boucle de décision en temps réel représente une direction émergente : elle permet d'exploiter le raisonnement de sens commun de ces modèles sans avoir à coder explicitement chaque scénario possible. Encore limité à la simulation, le système devra prouver sa robustesse et sa faible latence en conditions réelles, mais les auteurs y voient une voie crédible vers une conduite autonome réellement interactive et digne de confiance dans un trafic dense.
Vu une erreur factuelle dans cet article ? Signalez-la. Toutes les corrections valides sont publiées sur /corrections.