
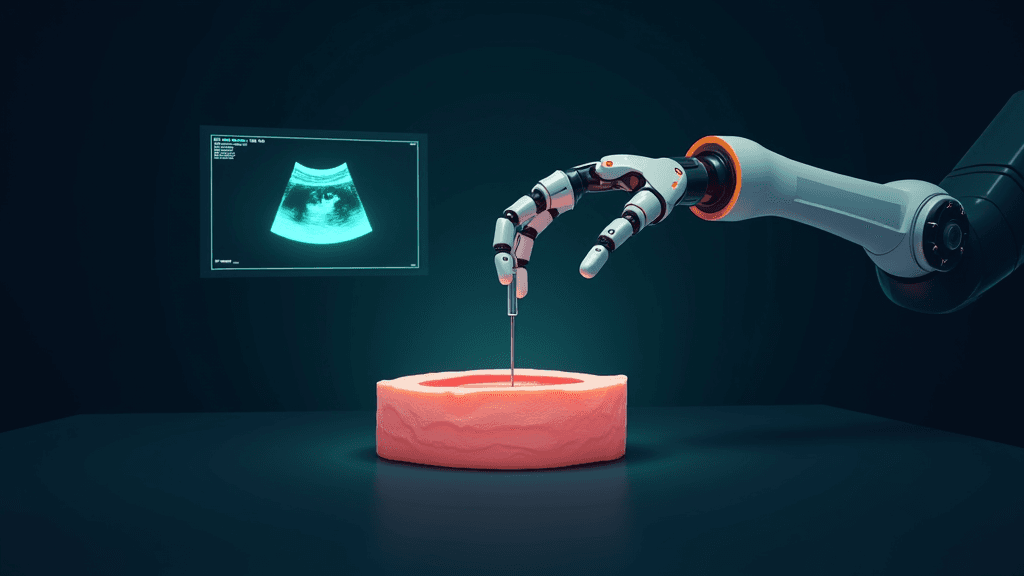
Un modèle vision-langage-action pour l'insertion et le suivi d'aiguille guidés par échographie
Des chercheurs ont présenté un nouveau système robotique capable de réaliser des insertions d'aiguille guidées par échographie de façon entièrement automatisée et adaptative. Publiée sur arXiv (arXiv:2504.20347), l'étude introduit un modèle de type Vision-Language-Action (VLA) intégré à un système d'échographie robotique (RUS). Le cadre repose sur deux composants clés développés par l'équipe : une tête de suivi baptisée Cross-Depth Fusion (CDF), qui fusionne des caractéristiques visuelles superficielles et sémantiques profondes pour localiser l'aiguille en temps réel, et un registre de conditionnement appelé TraCon (Tracking-Conditioning), qui adapte efficacement un modèle visuel pré-entraîné à grande échelle aux tâches de suivi sans réentraînement complet. À ces composants s'ajoutent une politique de contrôle tenant compte des incertitudes et un pipeline VLA asynchrone, permettant des décisions d'insertion rapides et contextuellement adaptées.
L'importance de cette avancée est directe : les insertions d'aiguille guidées par échographie sont omniprésentes en médecine, des biopsies aux anesthésies péridurales en passant par les ponctions vasculaires. Jusqu'ici, les systèmes automatisés reposaient sur des pipelines modulaires construits à la main, peu robustes face aux conditions d'imagerie difficiles, aux variations anatomiques ou aux mouvements du patient. Le nouveau système unifie suivi et contrôle dans un seul modèle bout-en-bout, ce qui lui permet de surpasser en précision de suivi et en taux de succès d'insertion non seulement les méthodes automatisées existantes, mais aussi les opérateurs humains lors des expériences menées, tout en réduisant le temps de procédure.
Le guidage échographique reste l'une des modalités les plus utilisées pour les interventions percutanées, mais sa fiabilité dépend fortement de l'expérience du praticien et de la qualité de l'image, deux facteurs très variables en clinique. Les approches à base de vision par ordinateur ont progressé ces dernières années, mais aucune n'avait encore proposé un modèle aussi unifié et adaptatif. Ce travail s'inscrit dans une tendance plus large d'application des grands modèles multimodaux à la robotique chirurgicale, un domaine où des acteurs académiques et industriels comme Intuitive Surgical ou Activ Surgical investissent massivement. Les prochaines étapes naturelles concernent la validation sur des patients réels et l'intégration dans des blocs opératoires, avec toutes les contraintes réglementaires que cela implique.
La validation clinique et l'intégration en bloc opératoire devront se conformer au règlement européen sur les dispositifs médicaux (MDR), conditionnant tout déploiement futur en Europe.
Vu une erreur factuelle dans cet article ? Signalez-la. Toutes les corrections valides sont publiées sur /corrections.



