

Pourquoi l'IA physique 2.0 a besoin d'un retour à la réalité
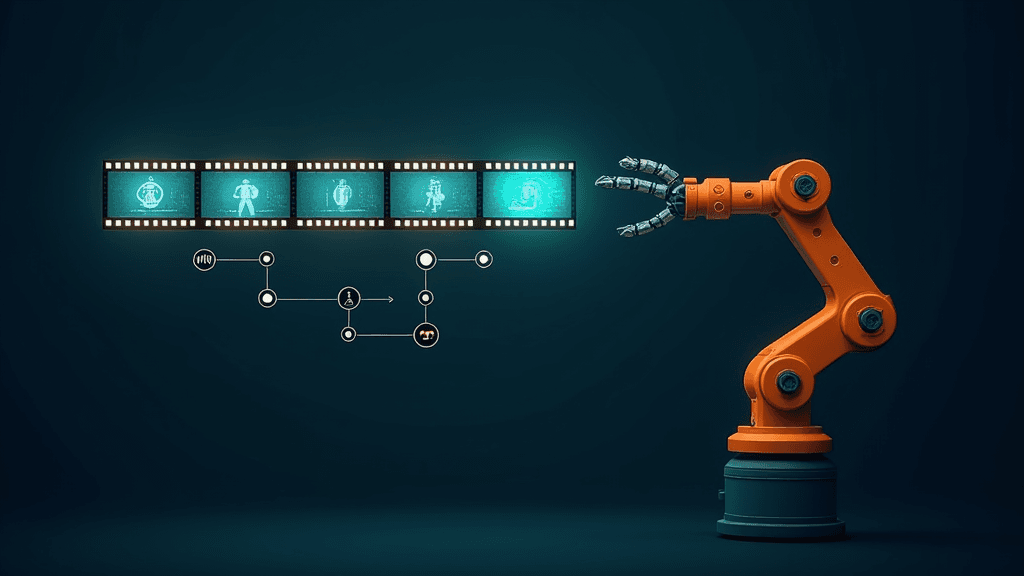
L'intelligence artificielle physique amorce une transition conceptuelle que le secteur commence à nommer "Physical AI 2.0". La première génération, aujourd'hui dominante, repose sur une logique de volume : des milliards de séquences vidéo et textuelles, complétées par des simulateurs hyperréalistes comme la plateforme Cosmos de NVIDIA, permettent d'entraîner des systèmes robotiques avant tout déploiement réel. Ce paradigme, qualifié de "vision-first", postule qu'avec suffisamment de caméras et de puissance de calcul, un robot peut modéliser et anticiper son environnement. Mais cette hypothèse se révèle fragile dès que les capteurs sont éblouis, que des objets sont occultés ou que les données sont bruitées et contradictoires. La "Physical AI 2.0" propose d'introduire une couche supplémentaire dans la pile logicielle : la récupération d'état physique (physical state recovery), qui reconstruit l'état réel du monde à partir de données incomplètes ou dégradées, avant même que le raisonnement de haut niveau n'entre en jeu. L'architecture cible comprend quatre briques en boucle fermée : des modèles du monde nourris par la simulation et l'expérience passée ; la récupération d'état physique ; un module de raisonnement qui sélectionne une intention ; et l'action, exécutée dans des contraintes de sécurité strictes. Le raisonnement n'actionne pas directement les effecteurs : il propose une intention, que la logique de planification et de sécurité traduit ensuite en mouvement borné. L'enjeu industriel est concret. Un robot qui mal-estime l'état de son environnement ne peut pas raisonner correctement, même si son modèle sous-jacent est de haute qualité : une mauvaise observation produit une erreur de raisonnement confiante, pas simplement une incertitude. La distinction clé est entre "cas difficile" et "cas mal observé". Un benchmark peut identifier qu'un système échoue dans des scénarios d'occlusion ou de comportements atypiques d'usagers de la route, sans pour autant corriger l'observation elle-même. Traiter la récupération d'état comme un module dédié, potentiellement alimenté par des capteurs spécialisés comme le radar ou des capteurs tactiles, évite à chaque nouveau robot de réapprendre les lois élémentaires de la physique depuis zéro. Pour les intégrateurs et décideurs B2B, la conséquence pratique est que l'unité de compétition dans l'IA physique n'est plus le modèle seul, mais l'ensemble de la chaîne : captation, simulation, entraînement de politique, orchestration, sécurité embarquée et boucle de retour terrain. Ce cadrage s'inscrit dans un débat plus large sur les limites des approches end-to-end dans la robotique et l'autonome. NVIDIA a investi massivement dans Cosmos pour normaliser la simulation physique, et plusieurs laboratoires explorent des architectures de type VLA (Vision-Language-Action) qui intègrent partiellement ces problématiques. L'argument central du texte est qu'agrandir indéfiniment des modèles bout-en-bout n'est pas la seule voie : une couche dédiée à la récupération d'état physique serait à la fois plus efficiente et plus robuste. À noter que ce texte est publié en amont de la conférence RoboBusiness 2026 et constitue essentiellement un cadrage conceptuel d'un positionnement produit, sans annonce ni déploiement commercial à la clé. Aucune métrique de performance concrète n'est avancée pour étayer la thèse, ce qui limite l'évaluation indépendante des affirmations.
































![[AINews] AI Engineer World's Fair : appel à conférenciers (agents autonomes, mémoire, modèles du monde, IA verticale)](/_next/image?url=https%3A%2F%2Fapi.lefilia.fr%2Fapi%2Fv1%2Fimages%2Farticle_2892971.png&w=1920&q=75)













