OpenJarvis : un framework local pour agents IA personnels avec outils, mémoire et apprentissage
Des chercheurs de l'Université Stanford et de Lambda Labs ont publié en mai 2026 OpenJarvis, un framework open-source conçu pour faire tourner des agents IA personnels entièrement en local, sans recours au cloud. Disponible sur GitHub avec déjà plus de 5 400 étoiles, le projet s'appuie sur onze modèles locaux issus de quatre familles (Qwen3.5, Gemma4, Nemotron, Granite) et supporte des moteurs d'inférence variés comme Ollama, vLLM ou llama.cpp. Les performances mesurées sur 508 tâches réparties en huit benchmarks montrent que les modèles configurés via OpenJarvis se situent à seulement 3,2 points de pourcentage en dessous des meilleurs modèles cloud, Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro, tout en affichant une latence quatre fois plus faible et un coût marginal par requête environ 800 fois inférieur.
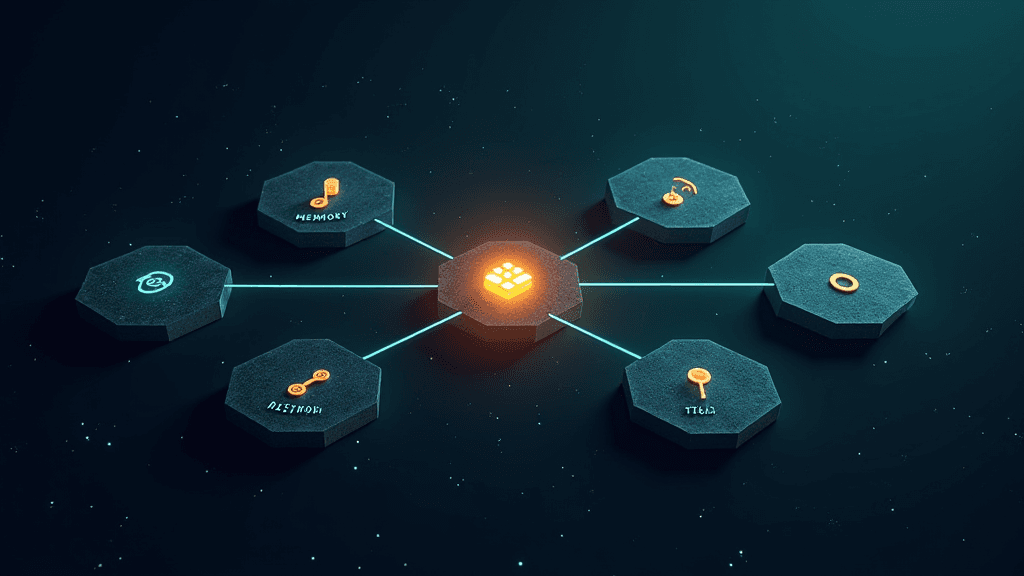
Ce résultat change concrètement l'équation pour les développeurs et les entreprises qui cherchent à déployer des agents IA sans dépendre d'APIs tierces. OpenJarvis décompose un système d'IA personnelle en cinq primitives indépendantes et interchangeables, le modèle, le moteur d'inférence, la logique d'agent, les outils et la mémoire, puis l'optimiseur d'apprentissage, toutes configurables via un unique fichier TOML appelé "spec". Cette architecture permet à un même comportement d'agent de fonctionner sur un Mac Mini M4 comme sur une station de travail NVIDIA DGX Spark, sans réécrire les prompts. L'installation tient en une seule commande et prend environ trois minutes sur une connexion correcte.
La contribution la plus originale du projet réside dans la "LLM-guided spec search", une méthode d'optimisation hybride locale-cloud : un modèle frontier agit comme enseignant au moment de la configuration, en analysant les traces d'exécution, diagnostiquant les échecs et proposant des modifications coordonnées sur l'ensemble des primitives. Une modification n'est acceptée que si elle améliore les cas défaillants sans provoquer de régressions ailleurs, avec une tolérance par défaut de 1%. Une fois optimisé, le système tourne entièrement en local sans aucun appel cloud. À 100 requêtes par jour, le coût amorti de cet enseignant descend sous 0,001 dollar par requête au bout de six mois. Cette approche multi-primitive récupère 13 à 32 points de pourcentage de l'écart cloud-local, contre seulement 5 points pour les optimiseurs de prompts classiques, à un coût d'optimisation 7 à 11 fois inférieur aux méthodes antérieures comme DSPy ou LoRA. Le projet s'inscrit dans un contexte où les modèles locaux gèrent déjà 88,7% des requêtes conversationnelles courantes selon une étude antérieure de la même équipe, et où l'efficacité des modèles embarqués a progressé de 5,3 fois entre 2023 et 2025.
Les entreprises européennes soumises au RGPD peuvent déployer des agents IA performants entièrement en local sans transférer leurs données vers des services cloud américains, réduisant leur exposition aux risques de non-conformité et renforçant leur souveraineté numérique.
3,2 points de moins que Claude Opus ou GPT-5, pour un coût 800 fois inférieur : à ce ratio, la question n'est plus "cloud ou local". Le truc malin c'est la spec search guidée, tu laisses un frontier calibrer ta config une fois, puis plus aucun appel cloud ensuite. Bon, faudra voir si leurs 508 tâches de benchmark ressemblent à ce qu'on rencontre vraiment en prod.
Dans nos dossiers
Vu une erreur factuelle dans cet article ? Signalez-la. Toutes les corrections valides sont publiées sur /corrections.