Construire un agent IA avancé avec planification, appel d'outils, mémoire et auto-critique via l'OpenAI API
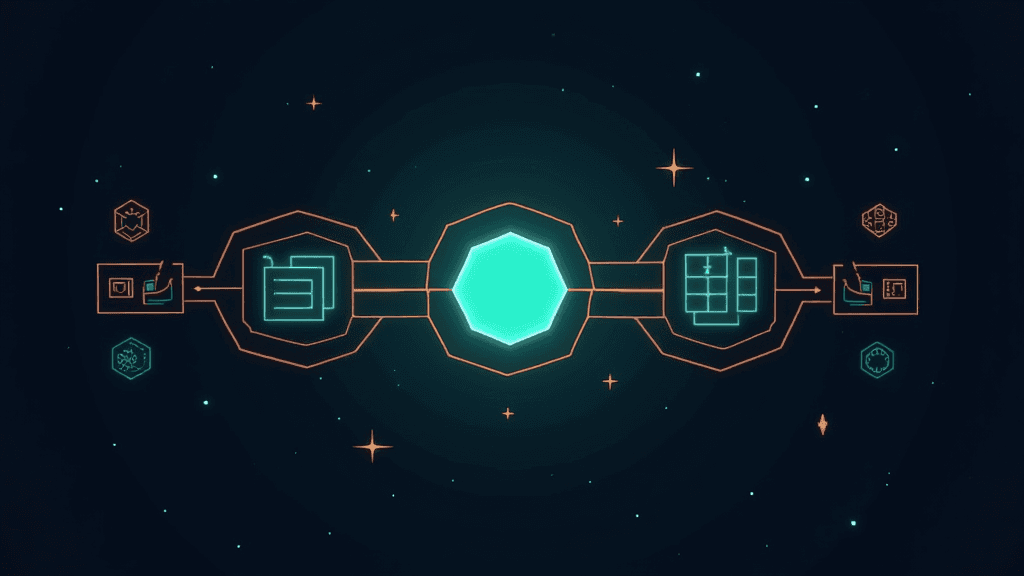
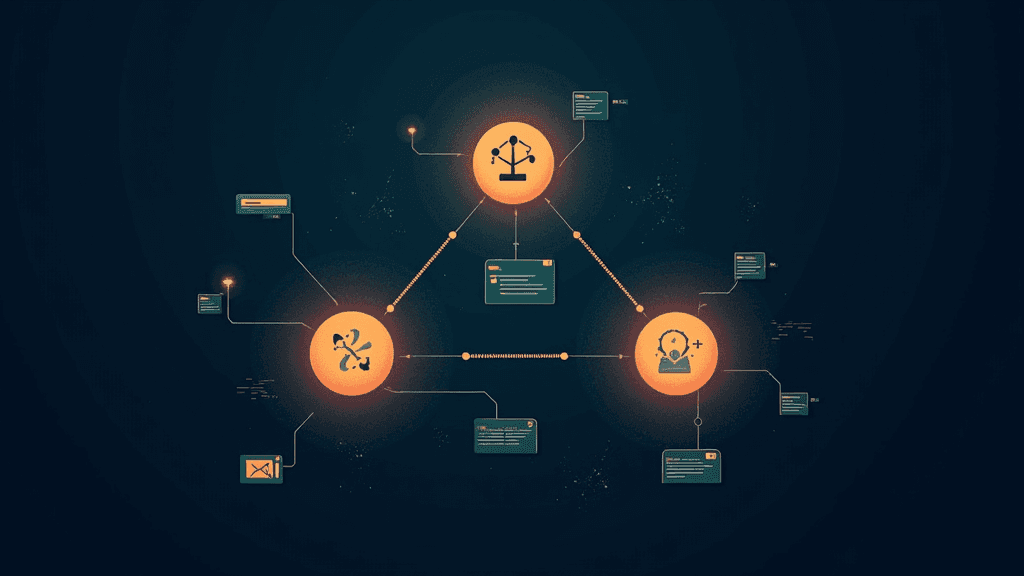
Un tutoriel publié sur la plateforme de notebooks Colab détaille comment construire un système d'IA agentique avancé en s'appuyant sur l'API OpenAI et le modèle GPT-5.2. L'architecture proposée repose sur un pipeline de trois rôles spécialisés et distincts : un planificateur qui décompose les objectifs complexes en étapes, un exécuteur qui mobilise des outils concrets pour agir, et un critique qui évalue la qualité des résultats avant de les valider. Quatre outils sont intégrés directement dans le système : une calculatrice sécurisée qui accepte uniquement des expressions numériques sans variables, un moteur de recherche dans une base de connaissances interne simulant des playbooks d'équipe, un extracteur JSON pour produire des sorties structurées, et un module d'écriture de fichiers qui sauvegarde les livrables finaux avec une empreinte SHA-256 de vérification. La clé API est transmise via getpass() pour éviter toute exposition dans le code ou les sorties du notebook.
Cette approche modulaire représente un changement de paradigme dans la façon de concevoir des agents IA. En séparant strictement la stratégie, l'action et le contrôle qualité en trois couches distinctes, le système évite les dérives courantes des agents monolithiques qui mélangent raisonnement et exécution sans garde-fous. Le composant critique intégré permet une autocorrection systématique avant la réponse finale, ce qui réduit les hallucinations et améliore la fiabilité des sorties dans des contextes professionnels. Pour les développeurs et les entreprises qui cherchent à automatiser des workflows complexes (rédaction de comptes-rendus de réunion, traitement de données structurées, génération de rapports), ce type d'architecture offre une robustesse que les chatbots conversationnels classiques ne peuvent pas atteindre.
Ce tutoriel s'inscrit dans une vague plus large d'intérêt pour les systèmes multi-agents et les architectures dites "agentic", portées notamment par les travaux d'Anthropic sur Claude, de Google avec Gemini, et d'OpenAI elle-même avec ses API d'assistants et de function calling. L'émergence de GPT-5.2, le modèle utilisé ici, illustre la rapidité avec laquelle les capacités de base progressent et rendent ces architectures accessibles à un plus grand nombre de développeurs. La tendance de fond est claire : les LLM cessent d'être de simples générateurs de texte pour devenir des orchestrateurs capables de planifier, d'agir sur des systèmes externes et de s'autocorriger, ce qui rapproche concrètement l'IA générative des promesses d'automatisation avancée que l'industrie promet depuis plusieurs années.
Vu une erreur factuelle dans cet article ? Signalez-la. Toutes les corrections valides sont publiées sur /corrections.