Créer un agent autonome à mémoire hybride avec architecture modulaire et appel d'outils via OpenAI
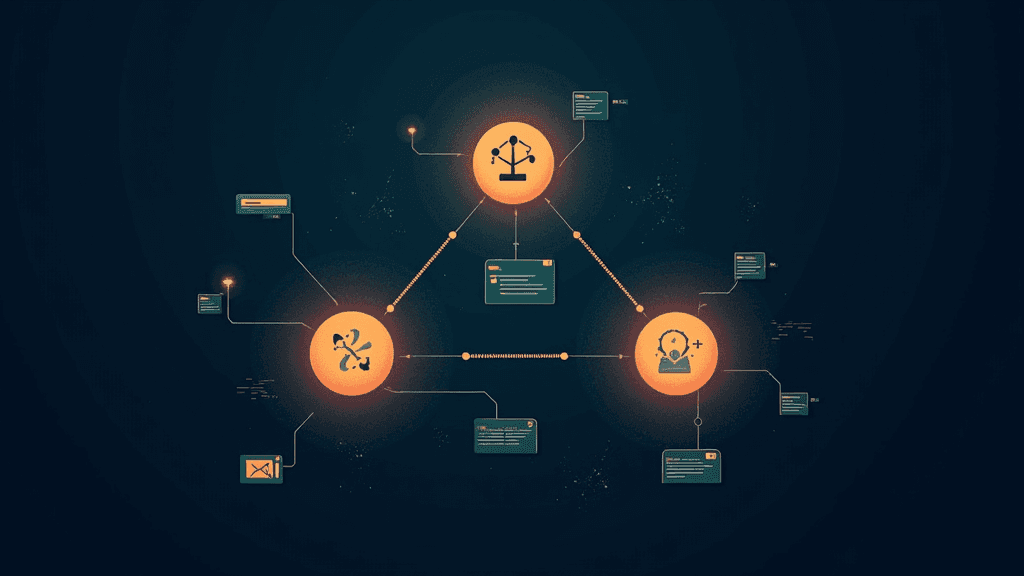
Un tutoriel technique récemment publié décrit la construction pas à pas d'un agent autonome à mémoire hybride, en s'appuyant sur l'API OpenAI et quelques bibliothèques Python open source. Le système combine deux mécanismes de recherche en mémoire : la recherche sémantique par vecteurs, via le modèle d'embedding text-embedding-3-small d'OpenAI, et la recherche par mots-clés via l'algorithme BM25, implémenté par la bibliothèque rank_bm25. Pour le raisonnement et la génération de texte, l'agent s'appuie sur gpt-4o-mini. L'architecture repose sur des interfaces abstraites Python (MemoryBackend, LLMProvider, Tool) qui séparent strictement chaque couche du système. Les résultats des deux moteurs de recherche sont ensuite fusionnés via la méthode Reciprocal Rank Fusion (RRF), une technique qui combine les classements plutôt que les scores bruts afin de produire des résultats plus robustes et équilibrés.
Ce type d'architecture représente un gain concret pour les développeurs qui souhaitent doter leurs agents d'une mémoire à long terme sans recourir à des bases de données vectorielles externes comme Pinecone ou Weaviate. En stockant les souvenirs sous forme de blocs de texte avec leurs embeddings directement en mémoire vive, et en reconstruisant l'index BM25 à chaque ajout, l'agent peut retrouver des informations pertinentes même lorsqu'une requête utilise des termes exacts absents du vocabulaire sémantique, un angle mort fréquent des systèmes purement vectoriels. Pour les équipes qui développent des assistants IA, des agents de recherche ou des chatbots d'entreprise, cette approche hybride offre un compromis entre précision sémantique et rappel lexical, deux qualités rarement réunies dans un seul système léger.
La mémoire persistante des agents autonomes reste l'un des grands défis non résolus du développement IA. Les grands modèles comme GPT-4o souffrent d'une fenêtre de contexte limitée et oublient ce qui dépasse quelques dizaines de milliers de tokens. Les architectures RAG (Retrieval-Augmented Generation) ont émergé pour compenser cette limite, mais la plupart des implémentations courantes misent soit sur la recherche vectorielle, soit sur les mots-clés, rarement les deux. Ce tutoriel s'inscrit dans une tendance portée par des frameworks comme LangChain, LlamaIndex ou MemGPT, qui poussent vers des agents dotés d'une mémoire modulaire et interrogeable. La prochaine étape naturelle est l'intégration d'une base de données persistante (SQLite, PostgreSQL) pour survivre aux redémarrages, et d'un mécanisme de compression sélective pour gérer la croissance de la mémoire dans le temps.
Dans nos dossiers
Vu une erreur factuelle dans cet article ? Signalez-la. Toutes les corrections valides sont publiées sur /corrections.