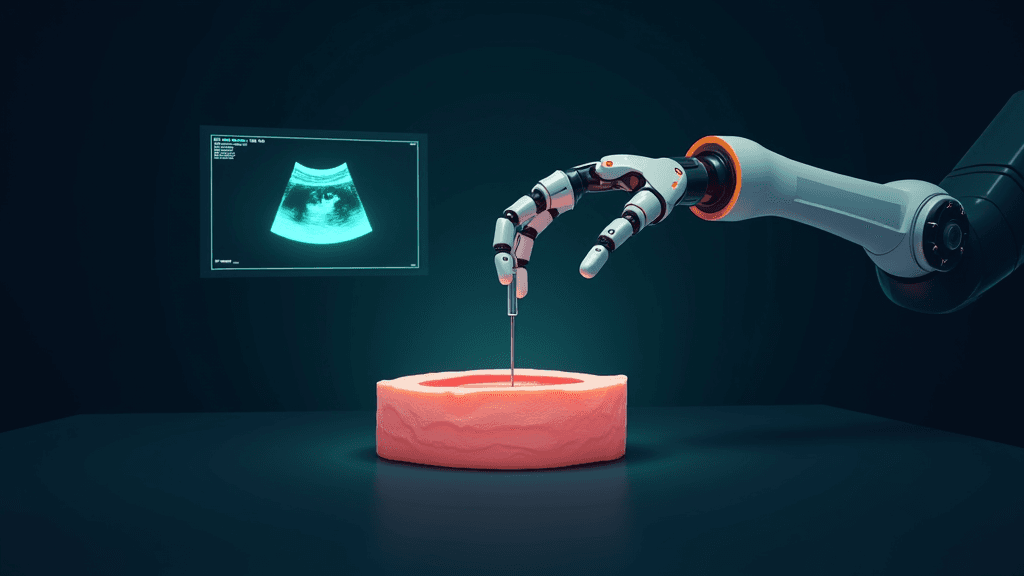
SAMe : un moteur de cartographie anatomique sémantique pour l'échographie robotique
Des chercheurs ont présenté SAMe, un moteur de cartographie anatomique sémantique conçu pour automatiser l'initialisation des examens d'échographie robotique. Publié sur arXiv (référence 2604.25646), ce système résout l'un des verrous majeurs de l'échographie autonome : savoir quoi scanner, où commencer et comment s'adapter à l'anatomie propre de chaque patient. Concrètement, SAMe fonctionne en trois étapes : il traduit une plainte clinique vague en organe cible précis, génère une représentation anatomique personnalisée à partir d'une simple photo externe du corps, puis calcule automatiquement la position et l'orientation de la sonde en six degrés de liberté, sans recours à une imagerie préopératoire IRM ou scanner. Lors des tests sur robot réel, SAMe a atteint un taux de localisation correcte de 97,3 % pour le foie et de 81,7 % pour le rein, surpassant dans les deux cas la méthode de référence basée sur des heuristiques de surface.
Ces résultats représentent une avancée décisive pour rendre l'échographie robotique véritablement autonome. Jusqu'ici, même les systèmes les plus sophistiqués dépendaient d'un expert humain pour initialiser le scan, c'est-à-dire positionner correctement la sonde en début d'examen. SAMe supprime cette dépendance en intégrant une couche de compréhension anatomique explicite directement dans la boucle de contrôle du robot. Le moteur est également très léger : l'inférence pour un organe prend seulement 0,08 seconde, ce qui le rend compatible avec des systèmes embarqués et des contextes cliniques temps réel.
L'échographie robotique se développe dans un contexte de tension croissante entre la demande mondiale d'imagerie médicale et la pénurie de spécialistes qualifiés, notamment dans les zones sous-dotées. Les systèmes existants avaient progressé sur le contrôle local de l'image et la régulation du contact avec la peau, mais butaient sur cette étape d'initialisation. SAMe s'inscrit dans une ambition plus large : des pipelines d'échographie autonome pilotés par la plainte du patient, sans intervention spécialisée à chaque étape. La prochaine étape attendue sera l'intégration de cette couche anatomique avec les modules de navigation et d'interprétation d'image pour former un système d'échographie entièrement autonome de bout en bout.
Vu une erreur factuelle dans cet article ? Signalez-la. Toutes les corrections valides sont publiées sur /corrections.