AMES : Recherche multimodale approximative en entreprise par extraction à interaction tardive
AMES (Approximate Multimodal Enterprise Search) marque une avancée significative dans le domaine de la recherche d'information en entreprise : cette nouvelle architecture unifiée permet d'interroger simultanément des textes, des images et des vidéos au sein d'un même moteur de recherche, sans nécessiter de refonte technique majeure des systèmes existants.
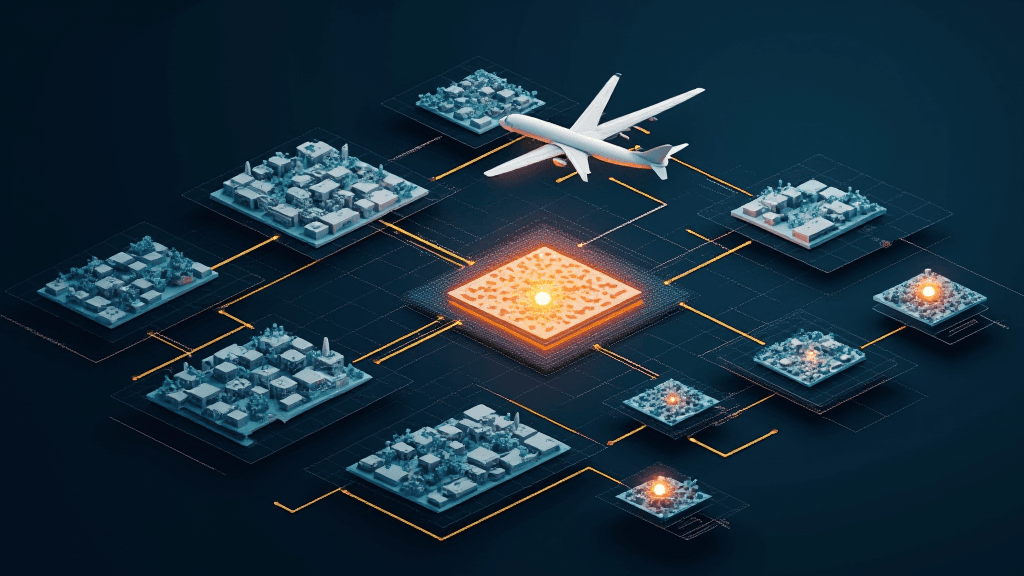
L'enjeu est considérable pour les organisations qui gèrent des volumes croissants de contenus hétérogènes. Jusqu'ici, la recherche multimodale exigeait généralement des pipelines distincts selon la nature du contenu — un pour le texte, un autre pour les images, etc. AMES brise cette logique en proposant une architecture agnostique du backend, compatible avec les infrastructures de recherche d'entreprise déjà en place, ce qui réduit drastiquement le coût et la complexité de déploiement.
Au cœur du système, une approche dite d'interaction tardive (late interaction) : les tokens textuels, les patches d'image et les frames vidéo sont encodés dans un espace de représentation partagé via des encodeurs multi-vecteurs. La récupération inter-modalités s'effectue sans logique spécifique à chaque modalité. Le pipeline repose sur deux étapes : une recherche ANN (Approximate Nearest Neighbor) parallèle au niveau token, suivie d'une phase de reclassement fin — garantissant ainsi précision et passage à l'échelle en environnement de production.
Cette approche s'inscrit dans la tendance de fond des systèmes RAG (Retrieval-Augmented Generation) multimodaux, où la qualité de la récupération conditionne directement la pertinence des réponses générées par les LLM. En rendant l'interaction tardive accessible sans redesign architectural, AMES pourrait accélérer l'adoption de la recherche multimodale dans les entreprises qui hésitaient encore à franchir le pas.
Vu une erreur factuelle dans cet article ? Signalez-la. Toutes les corrections valides sont publiées sur /corrections.