
Des données cloisonnées aux analyses unifiées : accès Athena multi-comptes dans Amazon QuickSight
Amazon vient d'annoncer une nouvelle fonctionnalité pour Amazon QuickSight, sa plateforme de business intelligence alimentée par l'IA : l'accès Athena inter-comptes (cross-account). Concrètement, les entreprises qui centralisent leur déploiement de QuickSight dans un seul compte AWS peuvent désormais interroger des données stockées dans d'autres comptes AWS via Amazon Athena, le service de requêtes SQL serverless d'Amazon qui analyse directement les données hébergées dans Amazon S3. Jusqu'à présent, ce scénario poussait les équipes à maintenir plusieurs abonnements QuickSight distincts, ou à faire absorber tous les coûts de requêtes par le compte central. Avec cette mise à jour, les frais de traitement sont facturés au compte où réside la donnée, et non au compte central.
L'impact est direct pour les grandes organisations financières, industrielles ou multidivisionnelles qui fonctionnent avec une architecture AWS multi-comptes. Une banque, par exemple, peut avoir ses données de banque de détail dans un compte A, ses activités d'investissement dans un compte B et sa gestion des risques dans un compte C, tout en pilotant QuickSight depuis un compte central unique. Cette nouvelle fonctionnalité supprime le besoin de dupliquer les abonnements ou de centraliser les coûts de façon artificielle. Elle simplifie aussi la gouvernance : chaque unité métier conserve la maîtrise de ses données et de sa facturation cloud, pendant que les équipes analytiques accèdent à l'ensemble depuis un tableau de bord unifié.
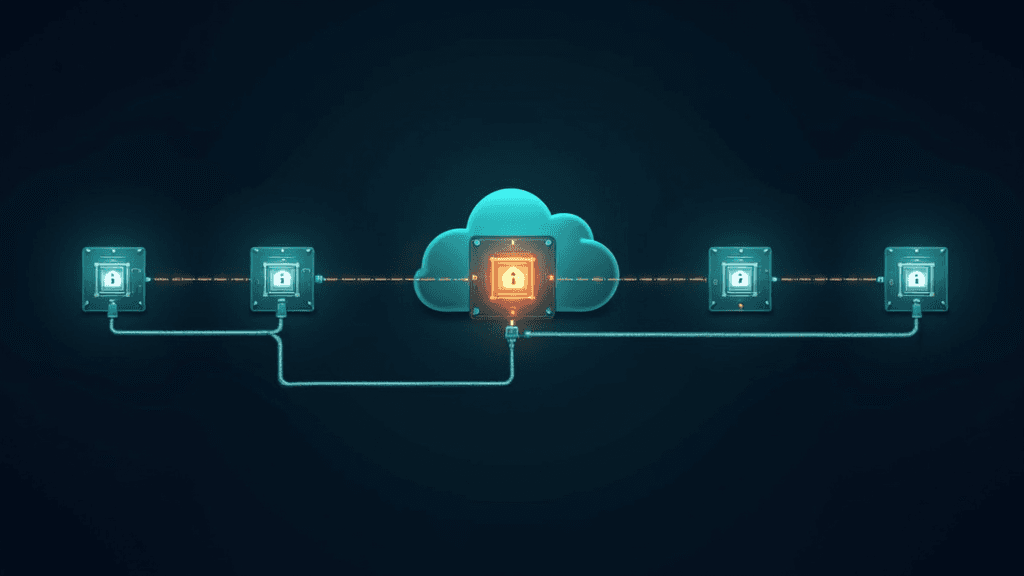
Le mécanisme technique repose sur un enchaînement de rôles IAM en deux étapes, appelé role chaining. QuickSight commence par endosser un rôle dit RunAsRole (Rôle A) dans le compte central, qui ne détient aucun accès aux données mais dispose uniquement de la permission de basculer vers un second rôle. Ce second rôle (Rôle B), situé dans le compte consommateur, détient lui les droits d'accès à Athena, au catalogue AWS Glue et aux fichiers S3. Pour éviter les attaques de type "confused deputy", un identifiant externe (ExternalId) lié à l'ARN de la source de données est intégré dans les politiques de confiance. Cette approche s'inscrit dans une tendance plus large d'AWS à décloisonner les silos de données tout en maintenant des contrôles d'accès granulaires, à mesure que les entreprises basculent vers des architectures data mesh distribuées où la donnée reste souveraine au niveau de chaque domaine métier.
Les grandes organisations européennes fonctionnant avec une architecture cloud multi-comptes peuvent désormais centraliser leurs analyses BI sans dupliquer les abonnements ni concentrer artificiellement les coûts, simplifiant la gouvernance des données distribuées.
Dans nos dossiers
Vu une erreur factuelle dans cet article ? Signalez-la. Toutes les corrections valides sont publiées sur /corrections.



