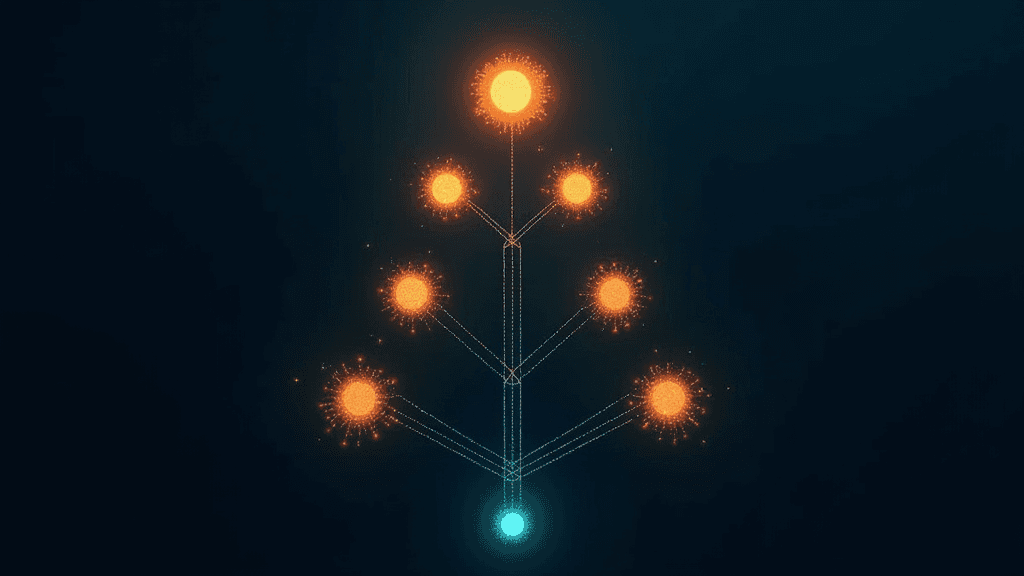
PORTool : optimisation de politique avec arbre de récompenses pour le raisonnement multi-outils
Des chercheurs ont publié PORTool, un algorithme d'optimisation de politique dit "importance-aware" conçu pour améliorer l'entraînement des agents LLM capables d'utiliser plusieurs outils simultanément. Le système introduit un arbre de récompenses (rewarded tree) qui attribue des crédits à chaque étape intermédiaire d'un raisonnement, plutôt qu'uniquement à l'issue finale d'une tâche. Concrètement, lorsqu'un agent enchaîne des appels à des outils externes avant de produire une réponse, PORTool est capable de noter individuellement chaque décision prise en cours de route.
Le problème central que PORTool cherche à résoudre est l'ambiguïté d'attribution de crédit, un obstacle persistant dans l'entraînement des agents multi-outils. Avec les méthodes classiques basées uniquement sur le résultat final, il est impossible de savoir quelles décisions intermédiaires ont contribué au succès ou à l'échec d'une séquence. Ce manque de granularité dégrade la qualité de l'apprentissage et rend les agents peu fiables en conditions réelles. PORTool offre un signal d'entraînement plus précis, ce qui devrait se traduire par des agents mieux capables de mobiliser les bons outils au bon moment.
Le raisonnement multi-outils est devenu un enjeu central depuis l'essor des agents autonomes comme GPT-4 avec plugins, ou les architectures ReAct et ToolLLM. Ces systèmes montrent un potentiel considérable pour automatiser des tâches complexes en milieu professionnel, mais leur fiabilité dépend directement de la qualité de leur entraînement. PORTool s'inscrit dans une vague de travaux sur l'apprentissage par renforcement appliqué aux LLM, un domaine en pleine effervescence depuis les succès de DeepSeek-R1 et d'autres modèles à raisonnement renforcé.
Dans nos dossiers
Vu une erreur factuelle dans cet article ? Signalez-la. Toutes les corrections valides sont publiées sur /corrections.