Guide pas à pas : pipeline d'optimisation de modèles avec NVIDIA Model Optimizer, élagage FastNAS et affinage
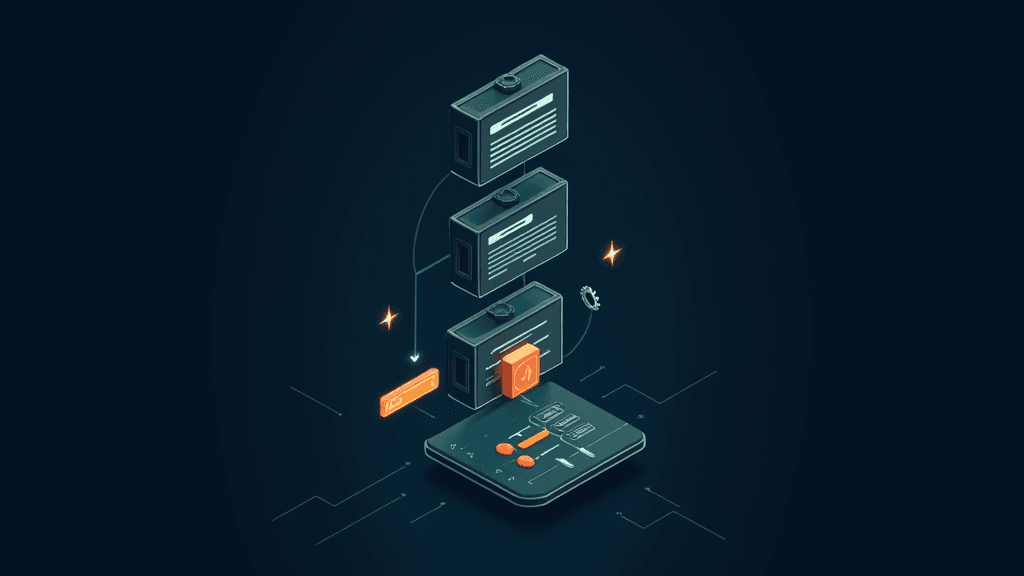
NVIDIA a publié un tutoriel complet détaillant comment construire un pipeline d'optimisation de bout en bout à l'aide de son outil NVIDIA Model Optimizer, combinant entraînement, élagage (pruning) et ajustement fin (fine-tuning) d'un réseau de neurones profond, le tout dans Google Colab sans infrastructure dédiée. Le pipeline repose sur l'architecture ResNet appliquée au jeu de données CIFAR-10, et utilise la technique FastNAS pour réduire la complexité computationnelle du modèle sous une contrainte de 60 millions de FLOPs (opérations en virgule flottante). Concrètement, le modèle est d'abord entraîné sur 12 000 exemples pendant 20 époques pour établir une référence, puis soumis à l'élagage structurel FastNAS qui supprime systématiquement les couches et filtres les moins utiles, avant une phase de fine-tuning de 12 époques pour récupérer la précision perdue.
Cette approche répond à un besoin pressant dans l'industrie : déployer des modèles d'IA performants sur des matériels contraints, comme les appareils embarqués, les téléphones mobiles ou les serveurs à faible consommation. En réduisant le nombre de FLOPs sans sacrifier significativement la précision, FastNAS permet de rendre un modèle jusqu'à plusieurs fois plus léger et plus rapide à l'inférence. Pour les équipes ML en entreprise, cela se traduit par des coûts de déploiement réduits, une latence moindre et une empreinte énergétique plus faible. Le fait que l'ensemble du pipeline soit reproductible dans Colab, avec gestion des seeds et des sous-ensembles de données, le rend accessible à des équipes sans cluster GPU dédié.
NVIDIA développe Model Optimizer dans le cadre de sa stratégie plus large pour contrôler toute la chaîne de valeur de l'IA, de l'entraînement jusqu'au déploiement sur ses propres puces. FastNAS s'inscrit dans une famille de techniques de compression de modèles qui inclut également la quantification et la distillation, toutes intégrées dans l'écosystème NVIDIA TensorRT. Face à la montée en puissance des outils open source comme la bibliothèque PEFT de Hugging Face ou les approches de pruning de PyTorch, NVIDIA positionne Model Optimizer comme une solution intégrée et orientée production. La prochaine étape logique de ce pipeline serait la conversion du modèle élaguévers le format ONNX ou TensorRT pour un déploiement sur GPU NVIDIA, bouclant ainsi la boucle entre recherche et mise en production industrielle.
Dans nos dossiers
Vu une erreur factuelle dans cet article ? Signalez-la. Toutes les corrections valides sont publiées sur /corrections.