
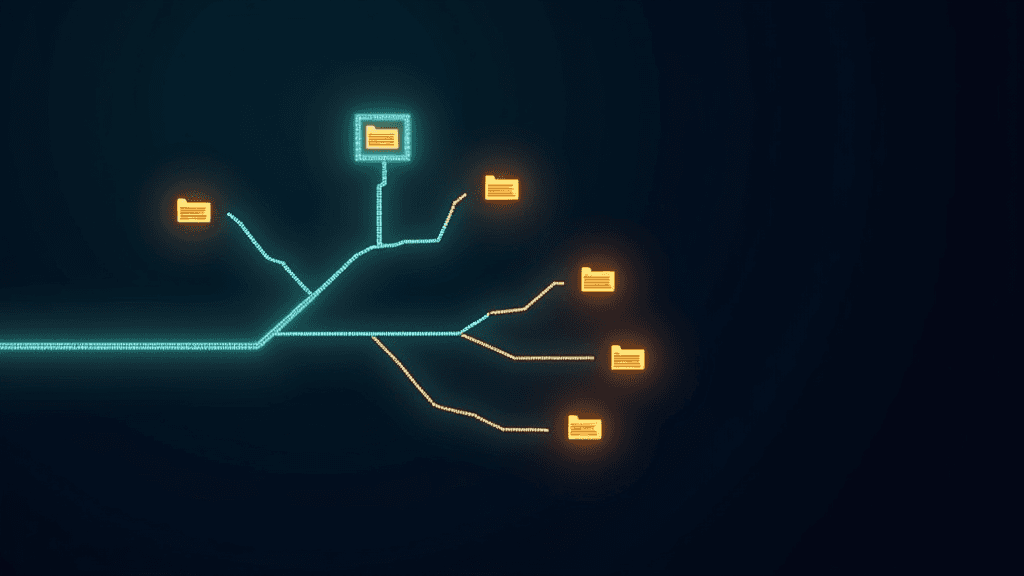
RAG sans vecteurs : PageIndex récupère l'information par raisonnement
PageIndex propose une alternative radicale aux systèmes de RAG (Retrieval-Augmented Generation) traditionnels : plutôt que de découper les documents en fragments et de rechercher les plus similaires par calcul vectoriel, la plateforme construit un index hiérarchique en forme d'arbre, modélisant la structure du document telle qu'elle existe, chapitres, sous-sections et titres imbriqués compris. Un modèle de langage comme GPT-5.4 raisonne ensuite sur cet arbre, navigue entre les noeuds et identifie les sections pertinentes avant même de lire le texte complet. La démonstration proposée porte sur le célèbre article scientifique "Attention Is All You Need", publié en 2017, qui a fondé l'architecture Transformer aujourd'hui omniprésente dans l'IA. Deux requêtes croisées sont posées sur ce document sans qu'un seul vecteur ou embedding ne soit calculé. Les performances de PageIndex ont été mesurées notamment sur FinanceBench, un benchmark spécialisé dans les documents financiers complexes, où l'approche surpasse significativement les pipelines vectoriels classiques.
L'enjeu dépasse la simple optimisation technique. Dans les rapports financiers, les textes juridiques ou les articles de recherche, la réponse à une question ne se trouve pas toujours dans le paragraphe "le plus proche" sémantiquement : elle exige de relier des informations dispersées sur plusieurs sections, de comprendre la structure du document et d'effectuer un raisonnement en plusieurs étapes. Les systèmes RAG classiques échouent silencieusement sur ce type de requêtes, en retournant des résultats plausibles mais inexacts. PageIndex rend le processus de récupération interprétable et traçable, ce qui est crucial pour les applications professionnelles où une hallucination ou une approximation peut avoir des conséquences réelles, que ce soit dans un cabinet d'avocats, une salle d'analyse financière ou un laboratoire de recherche.
Le RAG vectoriel s'est imposé comme l'architecture de référence pour connecter les LLM à des bases de connaissances externes depuis 2022-2023, porté par des bibliothèques comme LangChain ou LlamaIndex. Mais les limites de la recherche par similarité sémantique sont connues et documentées : les chunks perdent le contexte, les distances cosinus ne capturent pas la logique, et les documents longs déjouent systématiquement les pipelines standards. Plusieurs équipes cherchent des alternatives, comme GraphRAG de Microsoft, qui s'appuie sur des graphes de connaissances, ou les approches à base d'agents orchestrant plusieurs appels LLM. PageIndex s'inscrit dans cette tendance en pariant sur le raisonnement structuré plutôt que sur la puissance brute des embeddings. Avec l'arrivée de modèles toujours plus capables comme GPT-5.4, cette approche devient viable à grande échelle et pourrait redéfinir la manière dont les systèmes d'IA extraient l'information de documents complexes.
Le problème avec le RAG par chunks, c'est que tu perds la structure du document avant même d'avoir posé ta question. PageIndex fait le pari inverse : construire un arbre qui reflète l'organisation réelle du document, puis laisser le LLM naviguer dedans plutôt que de faire des calculs de distance cosinus à l'aveugle. Ça marche visiblement bien sur les docs financiers complexes, et pour les usages pro où une hallucination coûte cher, c'est exactement le bon angle d'attaque.
Vu une erreur factuelle dans cet article ? Signalez-la. Toutes les corrections valides sont publiées sur /corrections.


